![]()
The Best Google Professional-Machine-Learning-Engineer Study Guides and Dumps of 2022
Top Google Professional-Machine-Learning-Engineer Exam Audio Study Guide! Practice Questions Edition
For more info read reference:
NEW QUESTION 27
Given the following confusion matrix for a movie classification model, what is the true class frequency for Romance and the predicted class frequency for Adventure?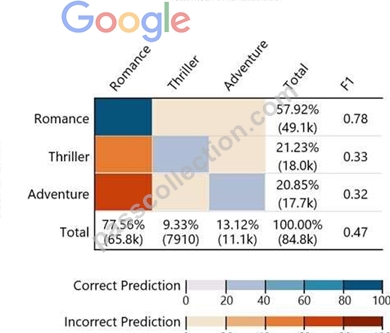
- A. The true class frequency for Romance is 57.92% and the predicted class frequency for Adventure is
13.12% - B. The true class frequency for Romance is 77.56% * 0.78 and the predicted class frequency for Adventure is
20.85%*0.32 - C. The true class frequency for Romance is 77.56% and the predicted class frequency for Adventure is
20.85% - D. The true class frequency for Romance is 0.78 and the predicted class frequency for Adventure is (0.47-
0.32)
Answer: A
NEW QUESTION 28
You have a functioning end-to-end ML pipeline that involves tuning the hyperparameters of your ML model using Al Platform, and then using the best-tuned parameters for training. Hypertuning is taking longer than expected and is delaying the downstream processes. You want to speed up the tuning job without significantly compromising its effectiveness. Which actions should you take?
Choose 2 answers
- A. Set the early stopping parameter to TRUE
- B. Decrease the maximum number of trials during subsequent training phases.
- C. Change the search algorithm from Bayesian search to random search.
- D. Decrease the range of floating-point values
- E. Decrease the number of parallel trials
Answer: C,D
NEW QUESTION 29
A Data Science team within a large company uses Amazon SageMaker notebooks to access data stored in Amazon S3 buckets. The IT Security team is concerned that internet-enabled notebook instances create a security vulnerability where malicious code running on the instances could compromise data privacy. The company mandates that all instances stay within a secured VPC with no internet access, and data communication traffic must stay within the AWS network.
How should the Data Science team configure the notebook instance placement to meet these requirements?
- A. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Use IAM policies to grant access to Amazon S3 and Amazon SageMaker.
- B. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Place the Amazon SageMaker endpoint and S3 buckets within the same VPC.
- C. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has S3 VPC endpoints and Amazon SageMaker VPC endpoints attached to it.
- D. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has a NAT gateway and an associated security group allowing only outbound connections to Amazon S3 and Amazon SageMaker.
Answer: C
NEW QUESTION 30
A data scientist has developed a machine learning translation model for English to Japanese by using Amazon SageMaker's built-in seq2seq algorithm with 500,000 aligned sentence pairs. While testing with sample sentences, the data scientist finds that the translation quality is reasonable for an example as short as five words. However, the quality becomes unacceptable if the sentence is 100 words long.
Which action will resolve the problem?
- A. Adjust hyperparameters related to the attention mechanism.
- B. Change preprocessing to use n-grams.
- C. Choose a different weight initialization type.
- D. Add more nodes to the recurrent neural network (RNN) than the largest sentence's word count.
Answer: D
NEW QUESTION 31
As the lead ML Engineer for your company, you are responsible for building ML models to digitize scanned customer forms. You have developed a TensorFlow model that converts the scanned images into text and stores them in Cloud Storage. You need to use your ML model on the aggregated data collected at the end of each day with minimal manual intervention. What should you do?
- A. Use the batch prediction functionality of Al Platform
- B. Use Cloud Functions for prediction each time a new data point is ingested
- C. Deploy the model on Al Platform and create a version of it for online inference.
- D. Create a serving pipeline in Compute Engine for prediction
Answer: C
NEW QUESTION 32
This graph shows the training and validation loss against the epochs for a neural network.
The network being trained is as follows:
* Two dense layers, one output neuron
* 100 neurons in each layer
* 100 epochs
* Random initialization of weights
Which technique can be used to improve model performance in terms of accuracy in the validation set?
- A. Random initialization of weights with appropriate seed
- B. Increasing the number of epochs
- C. Early stopping
- D. Adding another layer with the 100 neurons
Answer: B
NEW QUESTION 33
Your organization wants to make its internal shuttle service route more efficient. The shuttles currently stop at all pick-up points across the city every 30 minutes between 7 am and 10 am. The development team has already built an application on Google Kubernetes Engine that requires users to confirm their presence and shuttle station one day in advance. What approach should you take?
- A. 1. Define the optimal route as the shortest route that passes by all shuttle stations with confirmed attendance at the given time under capacity constraints.
2 Dispatch an appropriately sized shuttle and indicate the required stops on the map - B. 1. Build a reinforcement learning model with tree-based classification models that predict the presence of passengers at shuttle stops as agents and a reward function around a distance-based metric
2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the simulated outcome. - C. 1. Build a tree-based classification model that predicts whether the shuttle should pick up passengers at each shuttle station.
2. Dispatch an available shuttle and provide the map with the required stops based on the prediction - D. 1. Build a tree-based regression model that predicts how many passengers will be picked up at each shuttle station.
2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the prediction.
Answer: D
NEW QUESTION 34
You were asked to investigate failures of a production line component based on sensor readings. After receiving the dataset, you discover that less than 1% of the readings are positive examples representing failure incidents. You have tried to train several classification models, but none of them converge. How should you resolve the class imbalance problem?
- A. Use the class distribution to generate 10% positive examples
- B. Downsample the data with upweighting to create a sample with 10% positive examples
- C. Use a convolutional neural network with max pooling and softmax activation
- D. Remove negative examples until the numbers of positive and negative examples are equal
Answer: D
NEW QUESTION 35
A Data Science team within a large company uses Amazon SageMaker notebooks to access data stored in Amazon S3 buckets. The IT Security team is concerned that internet-enabled notebook instances create a security vulnerability where malicious code running on the instances could compromise data privacy. The company mandates that all instances stay within a secured VPC with no internet access, and data communication traffic must stay within the AWS network.
How should the Data Science team configure the notebook instance placement to meet these requirements?
- A. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Use IAM policies to grant access to Amazon S3 and Amazon SageMaker.
- B. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has S3 VPC endpoints and Amazon SageMaker VPC endpoints attached to it.
- C. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has a NAT gateway and an associated security group allowing only outbound connections to Amazon S3 and Amazon SageMaker.
- D. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Place the Amazon SageMaker endpoint and S3 buckets within the same VPC.
Answer: C
NEW QUESTION 36
You are an ML engineer at a large grocery retailer with stores in multiple regions. You have been asked to create an inventory prediction model. Your models features include region, location, historical demand, and seasonal popularity. You want the algorithm to learn from new inventory data on a daily basis. Which algorithms should you use to build the model?
- A. Recurrent Neural Networks (RNN)
- B. Convolutional Neural Networks (CNN)
- C. Classification
- D. Reinforcement Learning
Answer: D
NEW QUESTION 37
A company is using Amazon Polly to translate plaintext documents to speech for automated company announcements. However, company acronyms are being mispronounced in the current documents.
How should a Machine Learning Specialist address this issue for future documents?
- A. Use Amazon Lex to preprocess the text files for pronunciation
- B. Output speech marks to guide in pronunciation.
- C. Convert current documents to SSML with pronunciation tags.
- D. Create an appropriate pronunciation lexicon.
Answer: C
Explanation:
Explanation/Reference: https://docs.aws.amazon.com/polly/latest/dg/ssml.html
NEW QUESTION 38
A gaming company has launched an online game where people can start playing for free, but they need to pay if they choose to use certain features. The company needs to build an automated system to predict whether or not a new user will become a paid user within 1 year. The company has gathered a labeled dataset from 1 million users.
The training dataset consists of 1,000 positive samples (from users who ended up paying within 1 year) and
999,000 negative samples (from users who did not use any paid features). Each data sample consists of 200 features including user age, device, location, and play patterns.
Using this dataset for training, the Data Science team trained a random forest model that converged with over
99% accuracy on the training set. However, the prediction results on a test dataset were not satisfactory Which of the following approaches should the Data Science team take to mitigate this issue? (Choose two.)
- A. Generate more positive samples by duplicating the positive samples and adding a small amount of noise to the duplicated data.
- B. Change the cost function so that false negatives have a higher impact on the cost value than false positives.
- C. Change the cost function so that false positives have a higher impact on the cost value than false negatives.
- D. Include a copy of the samples in the test dataset in the training dataset.
- E. Add more deep trees to the random forest to enable the model to learn more features.
Answer: A,B
NEW QUESTION 39
A Machine Learning Specialist is required to build a supervised image-recognition model to identify a cat. The ML Specialist performs some tests and records the following results for a neural network-based image classifier:
Total number of images available = 1,000
Test set images = 100 (constant test set)
The ML Specialist notices that, in over 75% of the misclassified images, the cats were held upside down by their owners.
Which techniques can be used by the ML Specialist to improve this specific test error?
- A. Increase the dropout rate for the second-to-last layer.
- B. Increase the number of layers for the neural network.
- C. Increase the training data by adding variation in rotation for training images.
- D. Increase the number of epochs for model training
Answer: D
NEW QUESTION 40
You built and manage a production system that is responsible for predicting sales numbers. Model accuracy is crucial, because the production model is required to keep up with market changes. Since being deployed to production, the model hasn't changed; however the accuracy of the model has steadily deteriorated. What issue is most likely causing the steady decline in model accuracy?
- A. Incorrect data split ratio during model training, evaluation, validation, and test
- B. Lack of model retraining
- C. Too few layers in the model for capturing information
- D. Poor data quality
Answer: A
NEW QUESTION 41
A city wants to monitor its air quality to address the consequences of air pollution. A Machine Learning Specialist needs to forecast the air quality in parts per million of contaminates for the next 2 days in the city. As this is a prototype, only daily data from the last year is available.
Which model is MOST likely to provide the best results in Amazon SageMaker?
- A. Use the Amazon SageMaker Linear Learner algorithm on the single time series consisting of the full year of data with a predictor_typeof classifier.
- B. Use Amazon SageMaker Random Cut Forest (RCF) on the single time series consisting of the full year of data.
- C. Use the Amazon SageMaker k-Nearest-Neighbors (kNN) algorithm on the single time series consisting of the full year of data with a predictor_typeof regressor.
- D. Use the Amazon SageMaker Linear Learner algorithm on the single time series consisting of the full year of data with a predictor_typeof regressor.
Answer: D
Explanation:
Explanation/Reference: https://aws.amazon.com/blogs/machine-learning/build-a-model-to-predict-the-impact-of-weather- on-urban-air-quality-using-amazon-sagemaker/?ref=Welcome.AI
NEW QUESTION 42
A company is observing low accuracy while training on the default built-in image classification algorithm in Amazon SageMaker. The Data Science team wants to use an Inception neural network architecture instead of a ResNet architecture.
Which of the following will accomplish this? (Choose two.)
- A. Create a support case with the SageMaker team to change the default image classification algorithm to Inception.
- B. Customize the built-in image classification algorithm to use Inception and use this for model training.
- C. Bundle a Docker container with TensorFlow Estimator loaded with an Inception network and use this for model training.
- D. Download and apt-get installthe inception network code into an Amazon EC2 instance and use this instance as a Jupyter notebook in Amazon SageMaker.
- E. Use custom code in Amazon SageMaker with TensorFlow Estimator to load the model with an Inception network, and use this for model training.
Answer: B,E
NEW QUESTION 43
A retail company is using Amazon Personalize to provide personalized product recommendations for its customers during a marketing campaign. The company sees a significant increase in sales of recommended items to existing customers immediately after deploying a new solution version, but these sales decrease a short time after deployment. Only historical data from before the marketing campaign is available for training.
How should a data scientist adjust the solution?
- A. Add user metadata and use the HRNN-Metadata recipe in Amazon Personalize.
- B. Use the event tracker in Amazon Personalize to include real-time user interactions.
- C. Implement a new solution using the built-in factorization machines (FM) algorithm in Amazon SageMaker.
- D. Add event type and event value fields to the interactions dataset in Amazon Personalize.
Answer: D
NEW QUESTION 44
You are developing a Kubeflow pipeline on Google Kubernetes Engine. The first step in the pipeline is to issue a query against BigQuery. You plan to use the results of that query as the input to the next step in your pipeline. You want to achieve this in the easiest way possible. What should you do?
- A. Use the BigQuery console to execute your query and then save the query results Into a new BigQuery table.
- B. Use the Kubeflow Pipelines domain-specific language to create a custom component that uses the Python BigQuery client library to execute queries
- C. Locate the Kubeflow Pipelines repository on GitHub Find the BigQuery Query Component, copy that component's URL, and use it to load the component into your pipeline. Use the component to execute queries against BigQuery
- D. Write a Python script that uses the BigQuery API to execute queries against BigQuery Execute this script as the first step in your Kubeflow pipeline
Answer: A
NEW QUESTION 45
A Mobile Network Operator is building an analytics platform to analyze and optimize a company's operations using Amazon Athena and Amazon S3.
The source systems send data in .CSV format in real time. The Data Engineering team wants to transform the data to the Apache Parquet format before storing it on Amazon S3.
Which solution takes the LEAST effort to implement?
- A. Ingest .CSV data from Amazon Kinesis Data Streams and use Amazon Glue to convert data into Parquet.
- B. Ingest .CSV data using Apache Kafka Streams on Amazon EC2 instances and use Kafka Connect S3 to serialize data as Parquet
- C. Ingest .CSV data from Amazon Kinesis Data Streams and use Amazon Kinesis Data Firehose to convert data into Parquet.
- D. Ingest .CSV data using Apache Spark Structured Streaming in an Amazon EMR cluster and use Apache Spark to convert data into Parquet.
Answer: A
Explanation:
Explanation/Reference:
NEW QUESTION 46
A data scientist needs to identify fraudulent user accounts for a company's ecommerce platform. The company wants the ability to determine if a newly created account is associated with a previously known fraudulent user.
The data scientist is using AWS Glue to cleanse the company's application logs during ingestion.
Which strategy will allow the data scientist to identify fraudulent accounts?
- A. Create a FindMatches machine learning transform in AWS Glue.
- B. Create an AWS Glue crawler to infer duplicate accounts in the source data.
- C. Execute the built-in FindDuplicates Amazon Athena query.
- D. Search for duplicate accounts in the AWS Glue Data Catalog.
Answer: A
Explanation:
Explanation/Reference: https://docs.aws.amazon.com/glue/latest/dg/machine-learning.html
NEW QUESTION 47
You are an ML engineer at a regulated insurance company. You are asked to develop an insurance approval model that accepts or rejects insurance applications from potential customers. What factors should you consider before building the model?
- A. Redaction, reproducibility, and explainability
- B. Traceability, reproducibility, and explainability
- C. Differential privacy federated learning, and explainability
- D. Federated learning, reproducibility, and explainability
Answer: A
NEW QUESTION 48
A data scientist uses an Amazon SageMaker notebook instance to conduct data exploration and analysis. This requires certain Python packages that are not natively available on Amazon SageMaker to be installed on the notebook instance.
How can a machine learning specialist ensure that required packages are automatically available on the notebook instance for the data scientist to use?
- A. Use the conda package manager from within the Jupyter notebook console to apply the necessary conda packages to the default kernel of the notebook.
- B. Install AWS Systems Manager Agent on the underlying Amazon EC2 instance and use Systems Manager Automation to execute the package installation commands.
- C. Create a Jupyter notebook file (.ipynb) with cells containing the package installation commands to execute and place the file under the /etc/init directory of each Amazon SageMaker notebook instance.
- D. Create an Amazon SageMaker lifecycle configuration with package installation commands and assign the lifecycle configuration to the notebook instance.
Answer: C
Explanation:
Explanation
Explanation/Reference: https://towardsdatascience.com/automating-aws-sagemaker-notebooks-2dec62bc2c84
NEW QUESTION 49
A Machine Learning Specialist is working with a large company to leverage machine learning within its products. The company wants to group its customers into categories based on which customers will and will not churn within the next 6 months. The company has labeled the data available to the Specialist.
Which machine learning model type should the Specialist use to accomplish this task?
- A. Linear regression
- B. Clustering
- C. Reinforcement learning
- D. Classification
Answer: D
Explanation:
The goal of classification is to determine to which class or category a data point (customer in our case) belongs to. For classification problems, data scientists would use historical data with predefined target variables AKA labels (churner/non-churner) - answers that need to be predicted - to train an algorithm. With classification, businesses can answer the following questions:
* Will this customer churn or not?
* Will a customer renew their subscription?
* Will a user downgrade a pricing plan?
* Are there any signs of unusual customer behavior?
Reference: https://www.kdnuggets.com/2019/05/churn-prediction-machine-learning.html
NEW QUESTION 50
A Machine Learning Specialist is assigned a TensorFlow project using Amazon SageMaker for training, and needs to continue working for an extended period with no Wi-Fi access.
Which approach should the Specialist use to continue working?
- A. Install Python 3 and boto3 on their laptop and continue the code development using that environment.
- B. Download TensorFlow from tensorflow.org to emulate the TensorFlow kernel in the SageMaker environment.
- C. Download the SageMaker notebook to their local environment, then install Jupyter Notebooks on their laptop and continue the development in a local notebook.
- D. Download the TensorFlow Docker container used in Amazon SageMaker from GitHub to their local environment, and use the Amazon SageMaker Python SDK to test the code.
Answer: A
Explanation:
Explanation
NEW QUESTION 51
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this: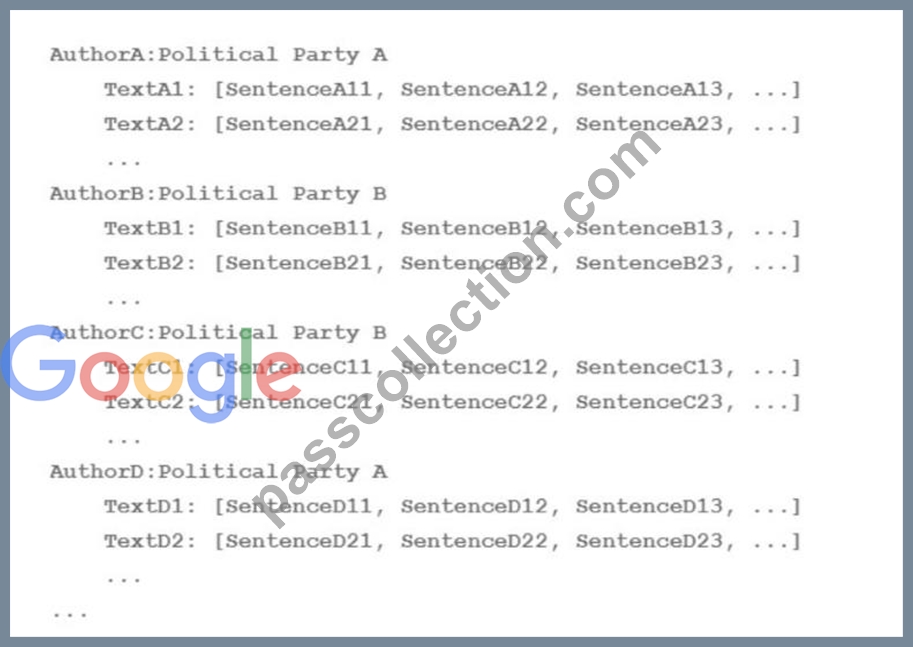
A)
B)
C)
D)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: C
NEW QUESTION 52
......
Valid Professional-Machine-Learning-Engineer Exam Updates - 2022 Study Guide: https://www.passcollection.com/Professional-Machine-Learning-Engineer_real-exams.html
Professional-Machine-Learning-Engineer Certification - The Ultimate Guide: https://drive.google.com/open?id=1RsR2QTffL_et1h2z86Vw6syv2ttorziG