![]()
[Jun 08, 2025] Professional-Machine-Learning-Engineer Exam Brain Dumps - Study Notes and Theory
Pass Google Professional-Machine-Learning-Engineer Test Practice Test Questions Exam Dumps
Google Professional Machine Learning Engineer certification is a highly respected and sought-after certification in the field of machine learning. Google Professional Machine Learning Engineer certification is designed to validate the skills and expertise of professionals who are responsible for designing, building, managing, and deploying machine learning models at scale using Google Cloud technologies. Google Professional Machine Learning Engineer certification exam covers a wide range of topics related to machine learning, and candidates must have a minimum of three years of experience in the field of machine learning to be eligible for the exam.
NEW QUESTION # 105
You have a large corpus of written support cases that can be classified into 3 separate categories: Technical Support, Billing Support, or Other Issues. You need to quickly build, test, and deploy a service that will automatically classify future written requests into one of the categories. How should you configure the pipeline?
- A. Use BigQuery ML to build and test a logistic regression model to classify incoming requests. Use BigQuery ML to perform inference.
- B. Use AutoML Natural Language to build and test a classifier. Deploy the model as a REST API.
- C. Create a TensorFlow model using Google's BERT pre-trained model. Build and test a classifier, and deploy the model using Vertex AI.
- D. Use the Cloud Natural Language API to obtain metadata to classify the incoming cases.
Answer: B
Explanation:
AutoML Natural Language is a service that allows you to quickly build, test and deploy natural language processing (NLP) models without needing to have expertise in NLP or machine learning. You can use it to train a classifier on your corpus of written support cases, and then use the AutoML API to perform classification on new requests. Once the model is trained, it can be deployed as a REST API. This allows the classifier to be integrated into your pipeline and be easily consumed by other systems.
NEW QUESTION # 106
Your company manages an application that aggregates news articles from many different online sources and sends them to users. You need to build a recommendation model that will suggest articles to readers that are similar to the articles they are currently reading. Which approach should you use?
- A. Create a collaborative filtering system that recommends articles to a user based on the user's past behavior.
- B. Build a logistic regression model for each user that predicts whether an article should be recommended to a user.
- C. Encode all articles into vectors using word2vec, and build a model that returns articles based on vector similarity.
- D. Manually label a few hundred articles, and then train an SVM classifier based on the manually classified articles that categorizes additional articles into their respective categories.
Answer: C
Explanation:
* Option A is incorrect because creating a collaborative filtering system that recommends articles to a user based on the user's past behavior is not the best approach to suggest articles that are similar to the articles they are currently reading. Collaborative filtering is a method of recommendation that uses the ratings or preferences of other users to predict the preferences of a target user1. However, this method does not consider the content or features of the articles, and may not be able to find articles that are similar in terms of topic, style, or sentiment.
* Option B is correct because encoding all articles into vectors using word2vec, and building a model that returns articles based on vector similarity is a suitable approach to suggest articles that are similar to the
* articles they are currently reading. Word2vec is a technique that learns low-dimensional and dense representations of words from a large corpus of text, such that words that are semantically similar have similar vectors2. By applying word2vec to the articles, we can obtain vector representations of the articles that capture their meaning and usage. Then, we can use a similarity measure, such as cosine similarity, to find articles that have similar vectors to the current article3.
* Option C is incorrect because building a logistic regression model for each user that predicts whether an article should be recommended to a user is not a feasible approach to suggest articles that are similar to the articles they are currently reading. Logistic regression is a supervised learning method that models the probability of a binary outcome (such as recommend or not) based on some input features (such as user profile or article content)4. However, this method requires a large amount of labeled data for each user, which may not be available or scalable. Moreover, this method does not directly measure the similarity between articles, but rather the likelihood of a user's preference.
* Option D is incorrect because manually labeling a few hundred articles, and then training an SVM classifier based on the manually classified articles that categorizes additional articles into their respective categories is not an effective approach to suggest articles that are similar to the articles they are currently reading. SVM (support vector machine) is a supervised learning method that finds a hyperplane that separates the data into different classes (such as news categories) with the maximum margin5. However, this method also requires a large amount of labeled data, which may be costly and time-consuming to obtain. Moreover, this method does not account for the fine-grained similarity between articles within the same category, or the cross-category similarity between articles from different categories.
References:
* Collaborative filtering
* Word2vec
* Cosine similarity
* Logistic regression
* SVM
NEW QUESTION # 107
You are developing an ML model that uses sliced frames from video feed and creates bounding boxes around specific objects. You want to automate the following steps in your training pipeline: ingestion and preprocessing of data in Cloud Storage, followed by training and hyperparameter tuning of the object model using Vertex AI jobs, and finallydeploying the model to an endpoint. You want to orchestrate the entire pipeline with minimal cluster management. What approach should you use?
- A. Use Vertex AI Pipelines with TensorFlow Extended (TFX) SDK.
- B. Use Vertex AI Pipelines with Kubeflow Pipelines SDK.
- C. Use Kubeflow Pipelines on Google Kubernetes Engine.
- D. Use Cloud Composer for the orchestration.
Answer: A
Explanation:
* Option A is incorrect because using Kubeflow Pipelines on Google Kubernetes Engine is not the most convenient way to orchestrate the entire pipeline with minimal cluster management. Kubeflow Pipelines is an open-source platform that allows you to build, run, and manage ML pipelines using containers1. Google Kubernetes Engine is a service that allows you to create and manage clusters of virtual machines that run Kubernetes, an open-source system for orchestrating containerized applications2. However, this option requires more effort and resources than option B, as it involves creating and configuring the clusters, installing and maintaining Kubeflow Pipelines, and writing and running the pipeline code.
* Option B is correct because using Vertex AI Pipelines with TensorFlow Extended (TFX) SDK is the best way to orchestrate the entire pipeline with minimal cluster management. Vertex AI Pipelines is a service that allows you to create and run scalable and portable ML pipelines on Google Cloud3. TensorFlow Extended (TFX) is a framework that provides a set of components and libraries for building production-ready ML pipelines using TensorFlow4. You can use Vertex AI Pipelines with TFX SDK to ingest and preprocess the data in Cloud Storage, train and tune the object model using Vertex AI jobs, and deploy the model to an endpoint, using predefined or custom components. Vertex AI Pipelines handles the underlying infrastructure and orchestration for you, so you don't need to worry about cluster management or scalability.
* Option C is incorrect because using Vertex AI Pipelines with Kubeflow Pipelines SDK is not the most suitable way to orchestrate the entire pipeline with minimal cluster management. Kubeflow Pipelines SDK is a library that allows you to build and run ML pipelines using Kubeflow Pipelines5. You can use Vertex AI Pipelines with Kubeflow Pipelines SDK to create and run ML pipelines on Google Cloud, using containers. However, this option is less convenient and consistent than option B, as it requires you to use different APIs and tools for different steps of the pipeline, such as Vertex AI SDK for training and deployment, and Kubeflow Pipelines SDK for ingestion and preprocessing. Moreover, this option does not leverage the benefits of TFX, such as the standard components, the metadata store, or the ML Metadata library.
* Option D is incorrect because using Cloud Composer for the orchestration is not the most efficient way to orchestrate the entire pipeline with minimal cluster management. Cloud Composer is a service that allows you to create and run workflows using Apache Airflow, an open-source platform for
* orchestrating complex tasks. You can use Cloud Composer to orchestrate the entire pipeline, by creating and managing DAGs (directed acyclic graphs) that define the dependencies and order of the tasks.
However, this option is more complex andcostly than option B, as it involves creating and configuring the environments, installing and maintaining Airflow, and writing and running the DAGs.
References:
* Kubeflow Pipelines documentation
* Google Kubernetes Engine documentation
* Vertex AI Pipelines documentation
* TensorFlow Extended documentation
* Kubeflow Pipelines SDK documentation
* [Cloud Composer documentation]
* [Vertex AI documentation]
* [Cloud Storage documentation]
* [TensorFlow documentation]
NEW QUESTION # 108
Your organization wants to make its internal shuttle service route more efficient. The shuttles currently stop at all pick-up points across the city every 30 minutes between 7 am and 10 am. The development team has already built an application on Google Kubernetes Engine that requires users to confirm their presence and shuttle station one day in advance. What approach should you take?
- A. 1. Build a reinforcement learning model with tree-based classification models that predict the presence of passengers at shuttle stops as agents and a reward function around a distance-based metric
2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the simulated outcome. - B. 1. Build a tree-based regression model that predicts how many passengers will be picked up at each shuttle station.
2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the prediction. - C. 1. Define the optimal route as the shortest route that passes by all shuttle stations with confirmed attendance at the given time under capacity constraints.
2 Dispatch an appropriately sized shuttle and indicate the required stops on the map - D. 1. Build a tree-based classification model that predicts whether the shuttle should pick up passengers at each shuttle station.
2. Dispatch an available shuttle and provide the map with the required stops based on the prediction
Answer: B
NEW QUESTION # 109
You are an ML engineer at an ecommerce company and have been tasked with building a model that predicts how much inventory the logistics team should order each month. Which approach should you take?
- A. Use a clustering algorithm to group popular items together. Give the list to the logistics team so they can increase inventory of the popular items.
- B. Use a time series forecasting model to predict each item's monthly sales. Give the results to the logistics team so they can base inventory on the amount predicted by the model.
- C. Use a regression model to predict how much additional inventory should be purchased each month. Give the results to the logistics team at the beginning of the month so they can increase inventory by the amount predicted by the model.
- D. Use a classification model to classify inventory levels as UNDER_STOCKED, OVER_STOCKED, and CORRECTLY_STOCKED. Give the report to the logistics team each month so they can fine-tune inventory levels.
Answer: B
Explanation:
The best approach to build a model that predicts how much inventory the logistics team should order each month is to use a time series forecasting model to predict each item's monthly sales. This approach can capture the temporal patterns and trends in the sales data, such as seasonality, cyclicality, and autocorrelation. It can also account for the variability and uncertainty in the demand, and provide confidence intervals and error metrics for the predictions. By using a time series forecasting model, you can provide the logistics team with accurate and reliable estimates of the future sales for each item, which can help them optimize the inventory levels and avoid overstocking or understocking. You can use various methods and tools to build a time series forecasting model, such as ARIMA, LSTM, Prophet, or BigQuery ML.
The other options are not optimal for the following reasons:
* A. Using a clustering algorithm to group popular items together is not a good approach, as it does not provide any quantitative or temporal information about the sales or the inventory. It only provides a qualitative and static categorization of the items based on their similarity or dissimilarity. Moreover, clustering is an unsupervised learning technique, which does not use any target variable or feedback to guide the learning process. This can result in arbitrary and inconsistent clusters, which may not reflect the true demand or preferences of the customers.
* B. Using a regression model to predict how much additional inventory should be purchased each month is not a good approach, as it does not account for the individual differences and dynamics of each item.
It only provides a single aggregated value for the whole inventory, which can be misleading and inaccurate. Moreover, a regression model is not well-suited for handling time series data, as it assumes that the data points are independent and identically distributed, which is not the case for sales data. A regression model can also suffer from overfitting or underfitting, depending on the choice and complexity of the features and the model.
* D. Using a classification model to classify inventory levels as UNDER_STOCKED, OVER_STOCKED, and CORRECTLY_STOCKED is not a good approach, as it does not provide any numerical or predictive information about the sales or the inventory. It only provides a discrete and subjective label for the inventory levels, which can be vague and ambiguous. Moreover, a classification model is not well-suited for handling time series data, as it assumes that the data points are independent and identically distributed, which is not the case for sales data. A classification model can also suffer
* from class imbalance, misclassification, or overfitting, depending on the choice and complexity of the features, the model, and the threshold.
References:
* Professional ML Engineer Exam Guide
* Preparing for Google Cloud Certification: Machine Learning Engineer Professional Certificate
* Google Cloud launches machine learning engineer certification
* Time Series Forecasting: Principles and Practice
* BigQuery ML: Time series analysis
NEW QUESTION # 110
You work for a social media company. You need to detect whether posted images contain cars. Each training example is a member of exactly one class. You have trained an object detection neural network and deployed the model version to Al Platform Prediction for evaluation. Before deployment, you created an evaluation job and attached it to the Al Platform Prediction model version. You notice that the precision is lower than your business requirements allow. How should you adjust the model's final layer softmax threshold to increase precision?
- A. Increase the number of false positives
- B. Decrease the number of false negatives
- C. Decrease the recall.
- D. Increase the recall
Answer: C
Explanation:
Precision and recall are two common metrics for evaluating the performance of a classification model.
Precision measures the proportion of positive predictions that are correct, while recall measures the proportion of positive examples that are correctly predicted. Precision and recall are inversely related, meaning that increasing one will decrease the other, and vice versa. The trade-off between precision and recall depends on the goal and the cost of the classification problem1.
For the use case of detecting whether posted images contain cars, precision is more important than recall, as the social media company wants to minimize the number of false positives, or images that are incorrectly labeled as containing cars. A high precision means that the model is confident and accurate in its positive predictions, while a low recall means that the model may miss some positive examples, or images that actually contain cars. The cost of missing some positive examples is lower than the cost of making wrong positive predictions, as the latter may affect the user experience and the reputation of the social media company.
The softmax function is a function that transforms a vector of real numbers into a probability distribution over the possible classes. The softmax function is often used as the final layer of a neural network for multi-class classification problems, as it assigns a probability to each class, and the class with the highest probability is chosen as the prediction. The softmax function is defined as:
softmax (x_i) = exp (x_i) / sum_j exp (x_j)
where x_i is the input value for class i, and softmax (x_i) is the output probability for class i.
The softmax threshold is a parameter that determines the minimum probability that a class must have to be chosen as the prediction. For example, if the softmax threshold is 0.5, then the class with the highest probability must have at least 0.5 to be selected, otherwise the prediction is none. The softmax threshold can be used to adjust the trade-off between precision and recall, as a higher threshold will increase the precision and decrease the recall, while a lower threshold will decrease the precision and increase the recall2.
For the use case of detecting whether posted images contain cars, the best way to adjust the model's final layer softmax threshold to increase precision is to decrease the recall. This means that the softmax threshold should be increased, so that the model will only make positive predictions when it is highly confident, and avoid making false positives. By increasing the softmax threshold, the model will become more selective and accurate in its positive predictions, and improve the precision metric. Therefore, decreasing the recall is the best option for this use case.
References:
* Precision and recall - Wikipedia
* How to add a threshold in softmax scores - Stack Overflow
NEW QUESTION # 111
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this: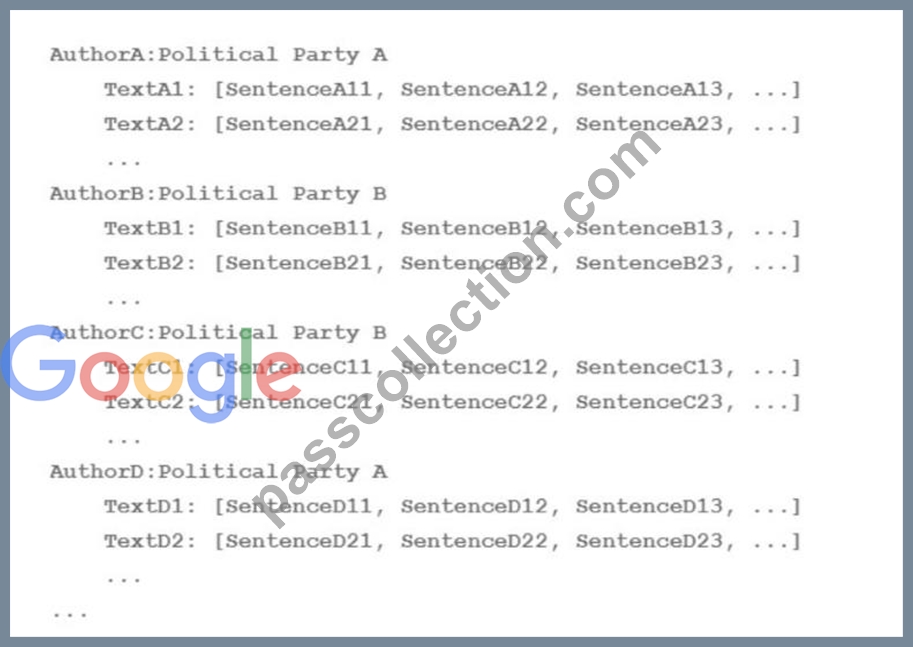
A)
B)
C)
D)
- A. Option B
- B. Option A
- C. Option C
- D. Option D
Answer: D
NEW QUESTION # 112
You work for an online retail company that is creating a visual search engine. You have set up an end-to-end ML pipeline on Google Cloud to classify whether an image contains your company's product. Expecting the release of new products in the near future, you configured a retraining functionality in the pipeline so that new data can be fed into your ML models. You also want to use Al Platform's continuous evaluation service to ensure that the models have high accuracy on your test data set. What should you do?
- A. Update your test dataset with images of the newer products when your evaluation metrics drop below a pre-decided threshold.
- B. Extend your test dataset with images of the newer products when they are introduced to retraining
- C. Replace your test dataset with images of the newer products when they are introduced to retraining.
- D. Keep the original test dataset unchanged even if newer products are incorporated into retraining
Answer: B
Explanation:
The test dataset is used to evaluate the performance of the ML model on unseen data. It should reflect the distribution of the data that the model will encounter in production. Therefore, if the retraining data includes new products, the test dataset should also be extended with images of those products to ensure that the model can generalize well to them. Keeping the original test dataset unchanged or replacing it entirely with images of the new products would not capture the diversity of the data that the model needs to handle. Updating the test dataset only when the evaluation metrics drop below a threshold would be reactive rather than proactive, and might result in poor user experience if the model fails to recognize the new products. Reference:
Continuous evaluation documentation
Preparing and using test sets
NEW QUESTION # 113
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is performing worse on the validation dat a. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
- A. Apply a 12 regularization parameter of 0.4, and decrease the learning rate by a factor of 10.
- B. Apply a dropout parameter of 0 2, and decrease the learning rate by a factor of 10
- C. Run a hyperparameter tuning job on Al Platform to optimize for the learning rate, and increase the number of neurons by a factor of 2.
- D. Run a hyperparameter tuning job on Al Platform to optimize for the L2 regularization and dropout parameters
Answer: D
Explanation:
https://machinelearningmastery.com/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
NEW QUESTION # 114
You started working on a classification problem with time series data and achieved an area under the receiver operating characteristic curve (AUC ROC) value of 99% for training data after just a few experiments. You haven't explored using any sophisticated algorithms or spent any time on hyperparameter tuning. What should your next step be to identify and fix the problem?
- A. Address data leakage by removing features highly correlated with the target value.
- B. Address the model overfitting by using a less complex algorithm.
- C. Address the model overfitting by tuning the hyperparameters to reduce the AUC ROC value.
- D. Address data leakage by applying nested cross-validation during model training.
Answer: D
Explanation:
https://towardsdatascience.com/time-series-nested-cross-validation-76adba623eb9
NEW QUESTION # 115
Your team has been tasked with creating an ML solution in Google Cloud to classify support requests for one of your platforms. You analyzed the requirements and decided to use TensorFlow to build the classifier so that you have full control of the model's code, serving, and deployment. You will use Kubeflow pipelines for the ML platform. To save time, you want to build on existing resources and use managed services instead of building a completely new model. How should you build the classifier?
- A. Use an established text classification model on Al Platform to perform transfer learning
- B. Use the Natural Language API to classify support requests
- C. Use AutoML Natural Language to build the support requests classifier
- D. Use an established text classification model on Al Platform as-is to classify support requests
Answer: A
Explanation:
Transfer learning is a technique that leverages the knowledge and weights of a pre-trained model and adapts them to a new task or domain1. Transfer learning can save time and resources by avoiding training a model from scratch, and can also improve the performance and generalization of the model by using a larger and more diverse dataset2. AI Platform provides several established text classification models that can be used for transfer learning, such as BERT, ALBERT, or XLNet3. These models are based on state-of-the-art natural language processing techniques and can handle various text classification tasks, such as sentiment analysis, topic classification, or spam detection4. By using one of these models on AI Platform, you can customize the model's code, serving, and deployment, and use Kubeflow pipelines for the ML platform. Therefore, using an established text classification model on AI Platform to perform transfer learning is the best option for this use case.
References:
* Transfer Learning - Machine Learning's Next Frontier
* A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning
* Text classification models
* Text Classification with Pre-trained Models in TensorFlow
NEW QUESTION # 116
You are developing a Kubeflow pipeline on Google Kubernetes Engine. The first step in the pipeline is to issue a query against BigQuery. You plan to use the results of that query as the input to the next step in your pipeline. You want to achieve this in the easiest way possible. What should you do?
- A. Write a Python script that uses the BigQuery API to execute queries against BigQuery Execute this script as the first step in your Kubeflow pipeline
- B. Use the BigQuery console to execute your query and then save the query results Into a new BigQuery table.
- C. Use the Kubeflow Pipelines domain-specific language to create a custom component that uses the Python BigQuery client library to execute queries
- D. Locate the Kubeflow Pipelines repository on GitHub Find the BigQuery Query Component, copy that component's URL, and use it to load the component into your pipeline. Use the component to execute queries against BigQuery
Answer: D
Explanation:
Kubeflow is an open source platform for developing, orchestrating, deploying, and running scalable and portable machine learning workflows on Kubernetes. Kubeflow Pipelines is a component of Kubeflow that allows you to build and manage end-to-end machine learning pipelines using a graphical user interface or a Python-based domain-specific language (DSL). Kubeflow Pipelines can help you automate and orchestrate your machine learning workflows, and integrate with various Google Cloud services and tools1 One of the Google Cloud services that you can use with Kubeflow Pipelines is BigQuery, which is a serverless, scalable, and cost-effective data warehouse that allows you to run fast and complex queries on large-scale data. BigQuery can help you analyze and prepare your data for machine learning, and store and manage your machine learning models2 To execute a query against BigQuery as the first step in your Kubeflow pipeline, and use the results of that query as the input to the next step in your pipeline, the easiest way to do that is to use the BigQuery Query Component, which is a pre-built component that you can find in the Kubeflow Pipelines repository on GitHub. The BigQuery Query Component allows you to run a SQL query on BigQuery, and output the results as a table or a file. You can use the component's URL to load the component into your pipeline, and specify the query and the output parameters. You can then use the output of the component as the input to the next step in your pipeline, such as a data processing or a model training step3 The other options are not as easy or feasible. Using the BigQuery console to execute your query and then save the query results into a new BigQuery table is not a good idea, as it does not integrate with your Kubeflow pipeline, and requires manual intervention and duplication of data. Writing a Python script that uses the BigQuery API to execute queries against BigQuery is not ideal, as it requires writing custom code and handling authentication and error handling. Using the Kubeflow Pipelines DSL to create a custom component that uses the Python BigQuery client library to execute queries is not optimal, as it requires creating and packaging a Docker container image for the component, and testing and debugging the component.
NEW QUESTION # 117
You are developing an image recognition model using PyTorch based on ResNet50 architecture. Your code is working fine on your local laptop on a small subsample. Your full dataset has 200k labeled images You want to quickly scale your training workload while minimizing cost. You plan to use 4 V100 GPUs. What should you do? (Choose Correct Answer and Give References and Explanation)
- A. Package your code with Setuptools. and use a pre-built container Train your model with Vertex Al using a custom tier that contains the required GPUs.
- B. Create a Vertex Al Workbench user-managed notebooks instance with 4 V100 GPUs, and use it to train your model
- C. Create a Google Kubernetes Engine cluster with a node pool that has 4 V100 GPUs Prepare and submit a TFJob operator to this node pool.
- D. Configure a Compute Engine VM with all the dependencies that launches the training Train your model with Vertex Al using a custom tier that contains the required GPUs.
Answer: A
Explanation:
The best option for scaling the training workload while minimizing cost is to package the code with Setuptools, and use a pre-built container. Train the model with Vertex AI using a custom tier that contains the required GPUs. This option has the following advantages:
* It allows the code to be easily packaged and deployed, as Setuptools is a Python tool that helps to create and distribute Python packages, and pre-built containers are Docker images that contain all the dependencies and libraries needed to run the code. By packaging the code with Setuptools, and using a pre-built container, you can avoid the hassle and complexity of building and maintaining your own custom container, and ensure the compatibility and portability of your code across different environments.
* It leverages the scalability and performance of Vertex AI, which is a fully managed service that provides various tools and features for machine learning, such as training, tuning, serving, and monitoring. By training the model with Vertex AI, you can take advantage of the distributed and parallel training capabilities of Vertex AI, which can speed up the training process and improve the model quality.
Vertex AI also supports various frameworks and models, such as PyTorch and ResNet50, and allows you to use custom containers and custom tiers to customize your training configuration and resources.
* It reduces the cost and complexity of the training process, as Vertex AI allows you to use a custom tier that contains the required GPUs, which can optimize the resource utilization and allocation for your training job. By using a custom tier that contains 4 V100 GPUs, you can match the number and type of GPUs that you plan to use for your training job, and avoid paying for unnecessary or underutilized resources. Vertex AI also offers various pricing options and discounts, such as per-second billing, sustained use discounts, and preemptible VMs, that can lower the cost of the training process.
The other options are less optimal for the following reasons:
* Option A: Configuring a Compute Engine VM with all the dependencies that launches the training.
Train the model with Vertex AI using a custom tier that contains the required GPUs, introduces additional complexity and overhead. This option requires creating and managing a Compute Engine VM, which is a virtual machine that runs on Google Cloud. However, using a Compute Engine VM to launch the training may not be necessary or efficient, as it requires installing and configuring all the dependencies and libraries needed to run the code, and maintaining and updating the VM. Moreover, using a Compute Engine VM to launch the training may incur additional cost and latency, as it requires paying for the VM usage and transferring the data and the code between the VM and Vertex AI.
* Option C: Creating a Vertex AI Workbench user-managed notebooks instance with 4 V100 GPUs, and using it to train the model, introduces additional cost and risk. This option requires creating and managing a Vertex AI Workbench user-managed notebooks instance, which is a service that allows you to create and run Jupyter notebooks on Google Cloud. However, using a Vertex AI Workbench user-managed notebooks instance to train the model may not be optimal or secure, as it requires paying for the notebooks instance usage, which can be expensive and wasteful, especially if the notebooks instance is not used for other purposes. Moreover, using a Vertex AI Workbench user-managed notebooks instance to train the model may expose the model and the data to potential security or privacy issues, as the notebooks instance is not fully managed by Google Cloud, and may be accessed or modified by unauthorized users or malicious actors.
* Option D: Creating a Google Kubernetes Engine cluster with a node pool that has 4 V100 GPUs.
Prepare and submit a TFJob operator to this node pool, introduces additional complexity and cost. This option requires creating and managing a Google Kubernetes Engine cluster, which is a fully managed
* service that runs Kubernetes clusters on Google Cloud. Moreover, this option requires creating and managing a node pool that has 4 V100 GPUs, which is a group of nodes that share the same configuration and resources. Furthermore, this option requires preparing and submitting a TFJob operator to this node pool, which is a Kubernetes custom resource that defines a TensorFlow training job. However, using Google Kubernetes Engine, node pool, and TFJob operator to train the model may not be necessary or efficient, as it requires configuring and maintaining the cluster, the node pool, and the TFJob operator, and paying for their usage. Moreover, using Google Kubernetes Engine, node pool, and TFJob operator to train the model may not be compatible or scalable, as they are designed for TensorFlow models, not PyTorch models, and may not support distributed or parallel training.
References:
* [Vertex AI: Training with custom containers]
* [Vertex AI: Using custom machine types]
* [Setuptools documentation]
* [PyTorch documentation]
* [ResNet50 | PyTorch]
NEW QUESTION # 118
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning Specialist would like to build a binary classifier based on two features: age of account and transaction month. The class distribution for these features is illustrated in the figure provided.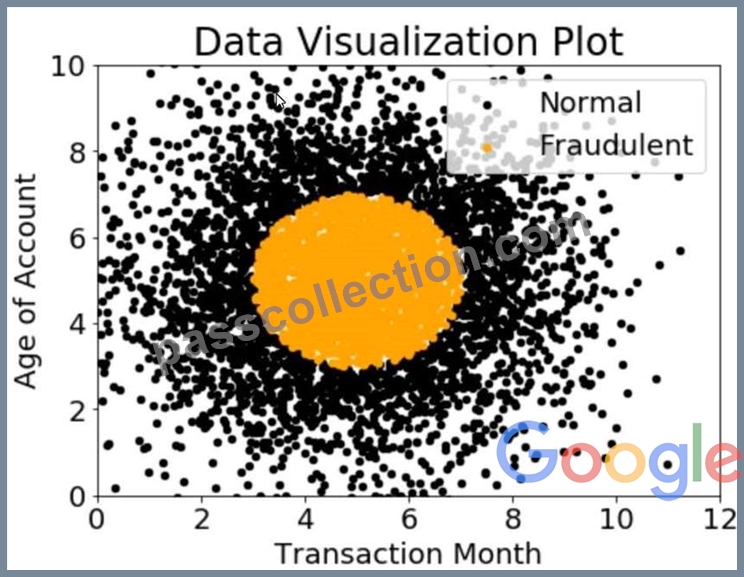
Based on this information, which model would have the HIGHEST accuracy?
- A. Logistic regression
- B. Single perceptron with tanh activation function
- C. Support vector machine (SVM) with non-linear kernel
- D. Long short-term memory (LSTM) model with scaled exponential linear unit (SELU)
Answer: C
NEW QUESTION # 119
You developed a Transformer model in TensorFlow to translate text Your training data includes millions of documents in a Cloud Storage bucket. You plan to use distributed training to reduce training time. You need to configure the training job while minimizing the effort required to modify code and to manage the clusters configuration. What should you do?
- A. Create a training job that uses Cloud TPU VMs Use tf.distribute.TPUStrategy for distribution.
- B. Create a Vertex Al custom distributed training job with Reduction Server Use N1 high-memory machine type instances for the first and second pools, and use N1 high-CPU machine type instances for the third worker pool.
- C. Create a Vertex Al custom training job with GPU accelerators for the second worker pool Use tf .distribute.MultiWorkerMirroredStrategy for distribution.
- D. Create a Vertex Al custom training job with a single worker pool of A2 GPU machine type instances Use tf .distribute.MirroredStraregy for distribution.
Answer: D
NEW QUESTION # 120
You are an ML engineer at a global shoe store. You manage the ML models for the company's website. You are asked to build a model that will recommend new products to the user based on their purchase behavior and similarity with other users. What should you do?
- A. Build a regression model using the features as predictors
- B. Build a knowledge-based filtering model
- C. Build a classification model
- D. Build a collaborative-based filtering model
Answer: D
Explanation:
Reference:
https://developers.google.com/machine-learning/recommendation/collaborative/basics
https://cloud.google.com/architecture/recommendations-using-machine-learning-on-compute-engine#filtering_the_data
NEW QUESTION # 121
A Machine Learning Specialist is required to build a supervised image-recognition model to identify a cat. The ML Specialist performs some tests and records the following results for a neural network-based image classifier:
Total number of images available = 1,000
Test set images = 100 (constant test set)
The ML Specialist notices that, in over 75% of the misclassified images, the cats were held upside down by their owners.
Which techniques can be used by the ML Specialist to improve this specific test error?
- A. Increase the dropout rate for the second-to-last layer.
- B. Increase the number of layers for the neural network.
- C. Increase the training data by adding variation in rotation for training images.
- D. Increase the number of epochs for model training
Answer: D
NEW QUESTION # 122
You are building a linear model with over 100 input features, all with values between -1 and 1. You suspect that many features are non-informative. You want to remove the non-informative features from your model while keeping the informative ones in their original form. Which technique should you use?
- A. Use L1 regularization to reduce the coefficients of uninformative features to 0.
- B. Use Principal Component Analysis to eliminate the least informative features.
- C. After building your model, use Shapley values to determine which features are the most informative.
- D. Use an iterative dropout technique to identify which features do not degrade the model when removed.
Answer: A
Explanation:
https://cloud.google.com/ai-platform/prediction/docs/ai-explanations/overview#sampled-shapley
NEW QUESTION # 123
......
Who should take the Professional Machine Learning Engineer - Google
A Professional Machine Learning Engineer designs, builds, and productionizes ML models to solve business challenges using Google Cloud technologies and knowledge of proven ML models and techniques. The ML Engineer collaborates closely with other job roles to ensure long-term success of models. The ML Engineer should be proficient in all aspects of model architecture, data pipeline interaction, and metrics interpretation. The ML Engineer needs familiarity with application development, infrastructure management, data engineering, and security. Through an understanding of training, retraining, deploying, scheduling, monitoring, and improving models, they design and create scalable solutions for optimal performance.
The Google Professional-Machine-Learning-Engineer exam is for entry-level IT specialists and organization professionals with standard knowledge of the Google platform. The Google CCP certification validates the potential client's understanding of these topics and their skills; standard building principles, key services and also their use cases, security, and protection, as well as compliance with the Google model, paid versions, and prices. Google Professional-Machine-Learning-Engineer exam is the appropriate starting point for Google certification and is also an excellent resource for those interested in non-technical projects.
Verified Professional-Machine-Learning-Engineer dumps Q&As - Professional-Machine-Learning-Engineer dumps with Correct Answers: https://www.passcollection.com/Professional-Machine-Learning-Engineer_real-exams.html
The Best Google Cloud Certified Study Guide for the Professional-Machine-Learning-Engineer Exam: https://drive.google.com/open?id=1cQhl8aOjwj0BfP8ifqEGOIBOCo1DvaYM